Data profiling with Power BI
Importance of Data Profiling
The analytics effort involves mashing and modelling data. In order to mash together the data we sometimes need to first understand the shape of the data.Power Query
Power Query has built-in functionality that provides us with a visual representation on the shape of the data.In order to demonstrate this, I have imported the Employee view from the Adventure Works 2017 OLTP database. Below is the Preview grid view in Power Query (you get here by clicking on the Edit Queries button)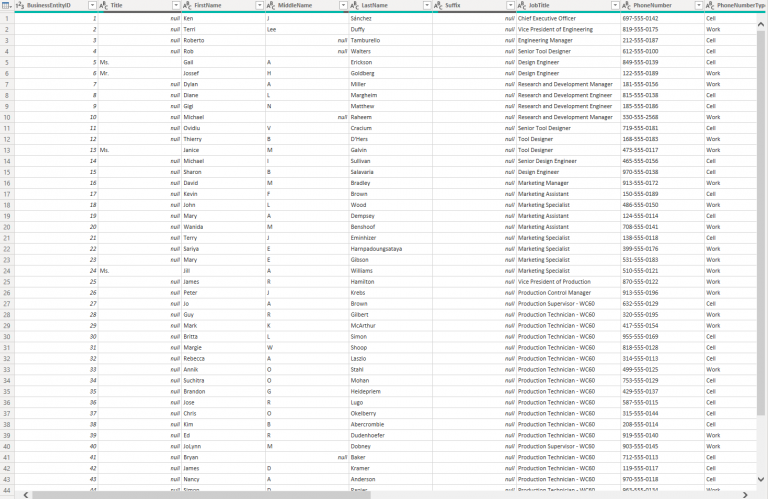 There are 3 options for data profiling in Power Query, found under the “View” menu
There are 3 options for data profiling in Power Query, found under the “View” menu- Column Quality
- Column Distribution
- Column Profile
 COLUMN QUALITYBy selecting “Column Quality” you are presented with a brief overview above each column on the percentage of data elements that are:
COLUMN QUALITYBy selecting “Column Quality” you are presented with a brief overview above each column on the percentage of data elements that are:- Valid (to the data type of the column)
- Error (to the data type of the column)
- Empty (number of records that are blank)
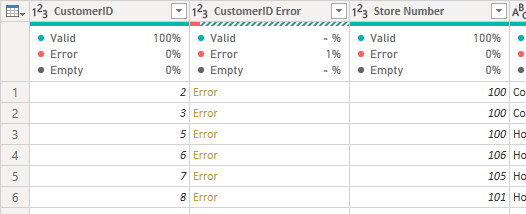 Empty ValuesIf any of the records in the column are null then they will be presented in the column quality statistic called “Empty”. See below example.
Empty ValuesIf any of the records in the column are null then they will be presented in the column quality statistic called “Empty”. See below example.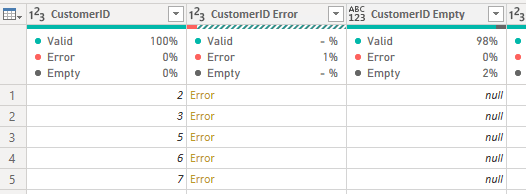 The Green Line HoverIn addition to being able to select “Column Quality”, you can achieve a similar outcome by hovering the cursor over the green line that sits under the column header (see above).By doing this you will get a tooltip providing information about the column quality (see below image)
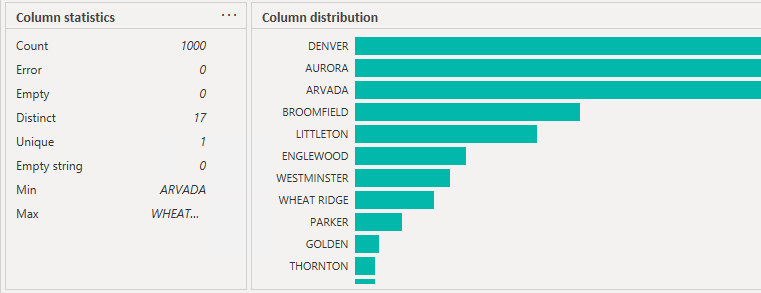
The Green Line HoverIn addition to being able to select “Column Quality”, you can achieve a similar outcome by hovering the cursor over the green line that sits under the column header (see above).By doing this you will get a tooltip providing information about the column quality (see below image)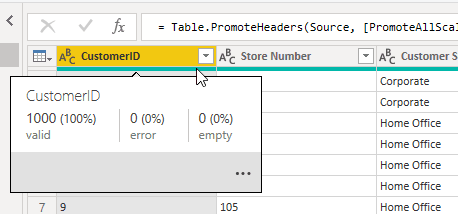 COLUMN DISTRIBUTIONSelecting the “Column Distribution” option provides a visual representation of the shape of the data, similar to a histogram. This option also presents us with some basic statistics regarding:
COLUMN DISTRIBUTIONSelecting the “Column Distribution” option provides a visual representation of the shape of the data, similar to a histogram. This option also presents us with some basic statistics regarding:- The number of distinct values
- The number of unique values
- Hover over the green line – data profile
- Column profiling based on only 1000 items. If larger table – select that message and change to “Entire data set”
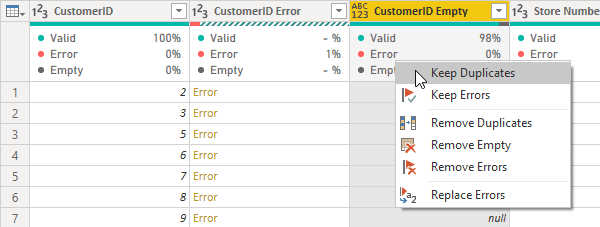 COLUMN PROFILEClicking on the “Column profile” option gives us a pane below the data preview grid.
COLUMN PROFILEClicking on the “Column profile” option gives us a pane below the data preview grid.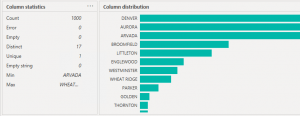 The Column distribution pane has 2 actions available:
The Column distribution pane has 2 actions available:
HOVER ACTION

RIGHT CLICK ACTION
Approach to Data Profiling
I find the best approach to data profiling with Power BI Desktop is to turn on all 3 options and click on the column that is of interested when you need more detailed information from the “Column profile” option.So basically “Column quality” and “Column distribution” provide at a glance view of all the columns in the query table and “Column profile” provides an in-depth view of a particular column that you need.Important Reminder!By default the profiling is done on the first 1000 records of the query result / table. As such if you want to profile the entire data set then you need to navigate to the bottom left of the data preview pane and click on the wording “Column profiling based on top 1000 rows” and change it to the entire data set (see below).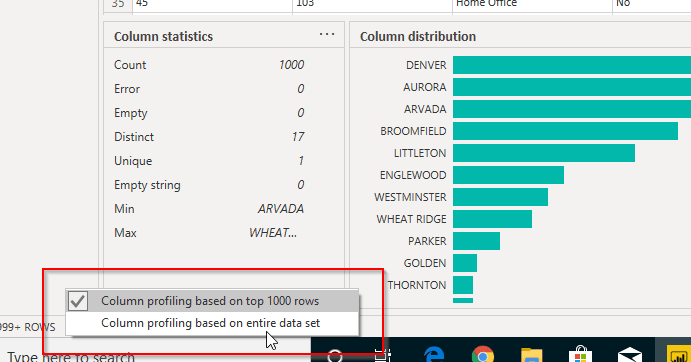 Have a great day !
Have a great day !Are you interested in knowing more about it?Let’s talk, we can help you!Contact | Lucid Insights
Check out the Lucid Insights blogThere is a variety of content that may help you to improve your business!